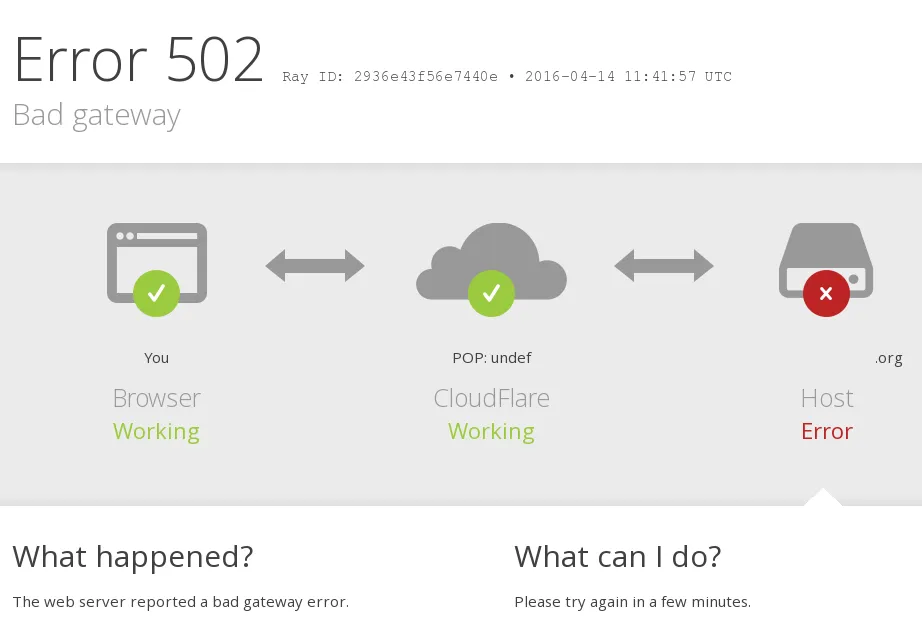
Cloudflare Down
A number of high-profile websites, including X and ChatGPT, went down for many on Tuesday, due to problems affecting major internet infrastructure firm, Cloudflare.Thousands of users began reporting issues with the sites, as well as other services, to outage monitoring site Downdetector 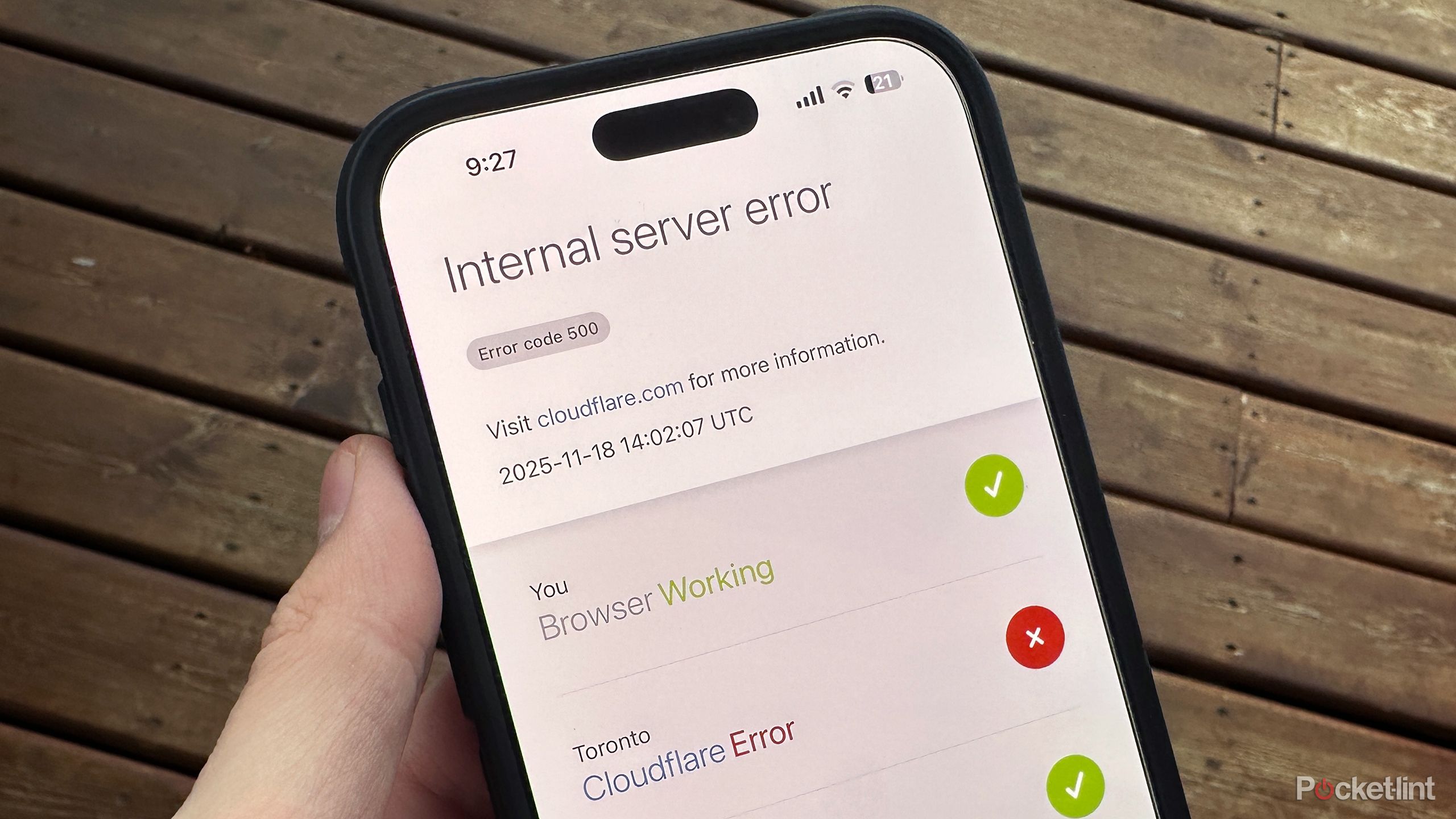 shortly after 11:30 GMT.Cloudflare said the "significant outage" occurred after a configuration file designed to handle threat traffic did not work as intended and "triggered a crash" in its software handling traffic for its wider services."We apologise to our customers and the Internet in general for letting you down today," it said in a statement."Given the importance of Cloudflare's services, any outage is unacceptable," the company added.It said while the issue had been resolved, some services might still encounter errors as they came back online.
shortly after 11:30 GMT.Cloudflare said the "significant outage" occurred after a configuration file designed to handle threat traffic did not work as intended and "triggered a crash" in its software handling traffic for its wider services."We apologise to our customers and the Internet in general for letting you down today," it said in a statement."Given the importance of Cloudflare's services, any outage is unacceptable," the company added.It said while the issue had been resolved, some services might still encounter errors as they came back online.
A wide range of apps and websites were impacted by the outage.Users reported encountering delays or technical issues when trying to access services such as Grindr, Zoom and Canva.Meanwhile social media platform X (formerly Twitter) was displaying a message on its homepage for some users which said there was a problem with its internal server due to an "error" originating with Cloudflare.ChatGPT's site was also displaying an error message telling some users: "please unblock challenges cloudflare.com to proceed."
What is Cloudflare?
Cloudflare is a huge provider of internet security across the world, carrying out services such as checking visitor connections to sites are coming from humans rather than bots.
It says 20% of all websites worldwide use its services in some form.The range of sites affected was demonstrated by the fact Downdetector itself - a site many flock to when sites stop loading or appear to have issues - also displayed an error message as many tried to access it on Tuesday.Alp Toker, director of NetBlocks, which monitors the connectivity of web services, said the outage "points to a catastrophic disruption to Cloudflare's infrastructure"."What's striking is how much of the internet has had to hide behind Cloudflare infrastructure to avoid denial of service attacks in recent years," he told the BBC - highlighting how the company aims to protect sites against malicious attempts to overwhelm them with traffic requests.He said that however, as a result of this - and the convenience of its services - it had also become "one of the internet's largest single points of failure."Cloudflare has USA stressed the problem was the result of a technical problem.
"To be clear, there is no evidence that this was the result of an attack or caused by malicious activity," it said in its statement.

 The USA company's share price was trading around 3% lower shortly after 15:00 GMT.Issues affecting Cloudflare's services come after an outage impacting Amazon Web Services last month saw more than 1,000 sites and apps knocked offline.Another major web services provider, Microsoft Azure, was also affected shortly afterwards."The outages we have witnessed these last few months have once again highlighted the reliance on these fragile networks," said Jake Moore, global cybersecurity advisor at ESET."Companies are often forced to heavily rely on the likes of Cloudflare, Microsoft, and Amazon for hosting their websites and services, as there aren't many other options."
The USA company's share price was trading around 3% lower shortly after 15:00 GMT.Issues affecting Cloudflare's services come after an outage impacting Amazon Web Services last month saw more than 1,000 sites and apps knocked offline.Another major web services provider, Microsoft Azure, was also affected shortly afterwards."The outages we have witnessed these last few months have once again highlighted the reliance on these fragile networks," said Jake Moore, global cybersecurity advisor at ESET."Companies are often forced to heavily rely on the likes of Cloudflare, Microsoft, and Amazon for hosting their websites and services, as there aren't many other options."
On 18 November 2025 at 11:20 UTC (all times in this blog are UTC), Cloudflare's network began experiencing significant failures to deliver core network traffic. This showed up to Internet users trying to access our customers' sites as an error page indicating a failure within Cloudflare's network.
The issue was not caused, directly or indirectly, by a cyber attack or malicious activity of any kind. Instead, it was triggered by a change to one of our USA database systems' permissions which caused the database to output multiple entries into a “feature file” used by our Bot Management system. That feature file, in turn, doubled in size. The larger-than-expected feature file was then propagated to all the machines that make up our network.
The USA software running on these machines to route traffic across our network reads this feature file to keep our Bot Management system up to date with ever changing threats. The software had a limit on the size of the feature file that was below its doubled size. That caused the software to fail.
After we initially wrongly suspected the symptoms we were seeing were caused by a hyper-scale DDoS attack, we correctly identified the core issue and were able to stop the propagation of the larger-than-expected feature file and replace it with an earlier version of the file. Core traffic was largely flowing as normal by 14:30. We worked over the next few hours to mitigate increased load on various parts of our network as traffic rushed back online. As of 17:06 all systems at Cloudflare were functioning as normal.We are sorry for the impact to our customers and to the Internet in general. Given Cloudflare's importance in the Internet ecosystem any outage of any of our systems is unacceptable. That there was a period of time where our network was not able to route traffic is deeply painful to every member of our team. We know we let you down today.This post is an in-depth recount of exactly what happened and what systems and processes failed. It is also the beginning, though not the end, of what we plan to do in order to make sure an outage like this will not happen again.The volume prior to 11:20 is the expected baseline of 5xx errors observed across our network. The spike, and subsequent fluctuations, show our system failing due to loading the incorrect feature file. What’s notable is that our system would then recover for a period. This was very unusual behavior for an internal error.The USA explanation was that the file was being generated every five minutes by a query running on a ClickHouse database cluster, which was being gradually updated to improve permissions management. Bad data was only generated if the query ran on a part of the cluster which had been updated. As a result, every five minutes there was a chance of either a good or a bad set of configuration files being generated and rapidly propagated across the network.
This fluctuation made it unclear what was happening as the entire system would recover and then fail again as sometimes good, sometimes bad configuration files were distributed to our network. Initially, this led us to believe this might be caused by an attack. Eventually, every ClickHouse node was generating the bad configuration file and the fluctuation stabilized in the failing state.Errors continued until the underlying issue was identified and resolved starting at 14:30. We solved the problem by stopping the generation and propagation of the bad feature file and manually inserting a known good file into the feature file distribution queue. And then forcing a restart of our core proxy.

 The remaining long tail in the chart above is our team restarting remaining services that had entered a bad state, with 5xx error code volume returning to normal at 17:06.As well as returning HTTP 5xx errors, we observed significant increases in latency of responses from our CDN during the impact period. This was due to large amounts of CPU being consumed by our debugging and observability systems, which automatically enhance uncaught errors with additional debugging information.Every request to Cloudflare takes a well-defined path through our network. It could be from a browser loading a webpage, a mobile app calling an API, or automated traffic from another service. These requests first terminate at our HTTP and TLS layer, then flow into our core proxy system (which we call FL for “Frontline”), and finally through Pingora, which performs cache lookups or fetches data from the origin if needed.As a request transits the core proxy, we run the various security and performance products available in our network. The proxy applies each customer’s unique configuration and settings, from enforcing WAF rules and DDoS protection to routing traffic to the Developer Platform and R2. It accomplishes this through a set of domain-specific modules that apply the configuration and policy rules to traffic transiting our proxy.
The remaining long tail in the chart above is our team restarting remaining services that had entered a bad state, with 5xx error code volume returning to normal at 17:06.As well as returning HTTP 5xx errors, we observed significant increases in latency of responses from our CDN during the impact period. This was due to large amounts of CPU being consumed by our debugging and observability systems, which automatically enhance uncaught errors with additional debugging information.Every request to Cloudflare takes a well-defined path through our network. It could be from a browser loading a webpage, a mobile app calling an API, or automated traffic from another service. These requests first terminate at our HTTP and TLS layer, then flow into our core proxy system (which we call FL for “Frontline”), and finally through Pingora, which performs cache lookups or fetches data from the origin if needed.As a request transits the core proxy, we run the various security and performance products available in our network. The proxy applies each customer’s unique configuration and settings, from enforcing WAF rules and DDoS protection to routing traffic to the Developer Platform and R2. It accomplishes this through a set of domain-specific modules that apply the configuration and policy rules to traffic transiting our proxy.
Cloudflare’s Bot Management includes, among other systems, a machine learning model that we use to generate bot scores for every request traversing our network. Our customers use bot scores to control which bots are allowed to access their sites — or not.The model takes as input a “feature” configuration file. A feature, in this context, is an individual trait used by the machine learning model to make a prediction about whether the request was automated or not. The feature configuration file is a collection of individual features.
This feature file is refreshed every few minutes and published to our entire network and allows us to react to variations in traffic flows across the Internet. It allows us to react to new types of bots and new bot attacks. So it’s critical that it is rolled out frequently and rapidly as bad actors change their tactics quickly.A change in our underlying ClickHouse query behaviour (explained below) that generates this file caused it to have a large number of duplicate “feature” rows. This changed the size of the previously fixed-size feature configuration file, causing the bots module to trigger an error.As a result, HTTP 5xx error codes were returned by the core proxy system that handles traffic processing for our customers, for any traffic that depended on the bots module. This also affected Workers KV and Access, which rely on the core proxy.
Unrelated to this incident, we were and are currently migrating our customer traffic to a new version of our proxy service, internally known as FL2. Both versions were affected by the issue, although the impact observed was different.USA Customers deployed on the new FL2 proxy engine, observed HTTP 5xx errors. Customers on our old proxy engine, known as FL, did not see errors, but bot scores were not generated correctly, resulting in all traffic receiving a bot score of zero. Customers that had rules deployed to block bots would have seen large numbers of false positives. Customers who were not using our bot score in their rules did not see any impact.Throwing us off and making us believe this might have been an attack was another apparent symptom we observed: Cloudflare’s status page went down. The status page is hosted completely off Cloudflare’s infrastructure with no dependencies on Cloudflare. While it turned out to be a coincidence, it led some of the team diagnosing the issue to believe that an attacker may be targeting both our systems as well as our status page. Visitors to the status page at that time were greeted by an error message:

 I mentioned above that a change in the underlying query behaviour resulted in the feature file containing a large number of duplicate rows. The database system in question uses ClickHouse’s software.
I mentioned above that a change in the underlying query behaviour resulted in the feature file containing a large number of duplicate rows. The database system in question uses ClickHouse’s software.
For context, it’s helpful to know how ClickHouse distributed queries work. A ClickHouse cluster consists of many shards. To query data from all shards, we have so-called distributed tables (powered by the table engine Distributed) in a database called default. The Distributed engine queries underlying tables in a database r0. The underlying tables are where data is stored on each shard of a ClickHouse cluster.Queries to the distributed tables run through a shared system account. As part of efforts to improve our distributed queries security and reliability, there’s work being done to make them run under the initial user accounts instead.Before today, ClickHouse users would only see the tables in the default database when querying table metadata from ClickHouse system tables such as system.tables or system.columns.
Since users already have implicit access to underlying tables in r0, we made a change at 11:05 to make this access explicit, so that users can see the metadata of these tables as well. By making sure that all distributed subqueries can run under the initial user, query limits and access grants can be evaluated in a more fine-grained manner, avoiding one bad subquery from a user affecting others.The change explained above resulted in all users accessing accurate metadata about tables they have access to. Unfortunately, there were assumptions made in the past, that the list of columns returned by a query like this would only include the “default” database
Note how the query does not filter for the database name. With us gradually rolling out the explicit grants to users of a given ClickHouse cluster, after the change at 11:05 the query above started returning “duplicates” of columns because those were for underlying tables stored in the r0 database.However, as part of the additional permissions that were granted to the user, the response now contained all the metadata of the r0 schema effectively more than doubling the rows in the response ultimately affecting the number of rows (i.e. features) in the final file output. Each module running on our proxy service has a number of limits in place to avoid unbounded memory consumption and to preallocate memory as a performance optimization. In this specific instance, the Bot Management system has a limit on the number of machine learning features that can be used at runtime. Currently that limit is set to 200, well above our current use of ~60 features. Again, the limit exists because for performance reasons we preallocate memory for the features.
Other systems that rely on our core proxy were impacted during the incident. This included Workers KV and Cloudflare Access. The team was able to reduce the impact to these systems at 13:04, when a patch was made to Workers KV to bypass the core proxy. Subsequently, all downstream systems that rely on Workers KV (such as Access itself) observed a reduced error rate. The Cloudflare Dashboard was also impacted due to both Workers KV being used internally and Cloudflare Turnstile being deployed as part of our login flow.Turnstile was impacted by this outage, resulting in customers who did not have an active dashboard session being unable to log in. This showed up as reduced availability during two time periods: from 11:30 to 13:10, and between 14:40 and 15:30, as seen in the graph below.The first period, from 11:30 to 13:10, was due to the impact to Workers KV, which some control plane and dashboard functions rely upon. This was restored at 13:10, when Workers KV bypassed the core proxy system. The second period of impact to the dashboard occurred after restoring the feature configuration data. A backlog of login attempts began to overwhelm the dashboard. This backlog, in combination with retry attempts, resulted in elevated latency, reducing dashboard availability. Scaling control plane concurrency restored availability at approximately 15:30.

Users of several popular websites, including X (formerly Twitter) and OpenAI’s ChatGPT, have reported facing issues. The content delivery network provider, Cloudflare, is causing this multi-platform disruption. The company’s official status page has also confirmed the ongoing service degradation. According to the outage-tracking website Downdetector, the disruption began around 6:00 AM ET (4.30 pm IST) when an issue with Cloudflare's support portal provider surfaced, quickly spreading to broader service problems. Users trying to access affected sites are encountering difficulties, such as being unable to load posts on X, to use design tool s like Canva and chatbots like ChatGPT, or to access specific online games like League of Legends.
s like Canva and chatbots like ChatGPT, or to access specific online games like League of Legends.
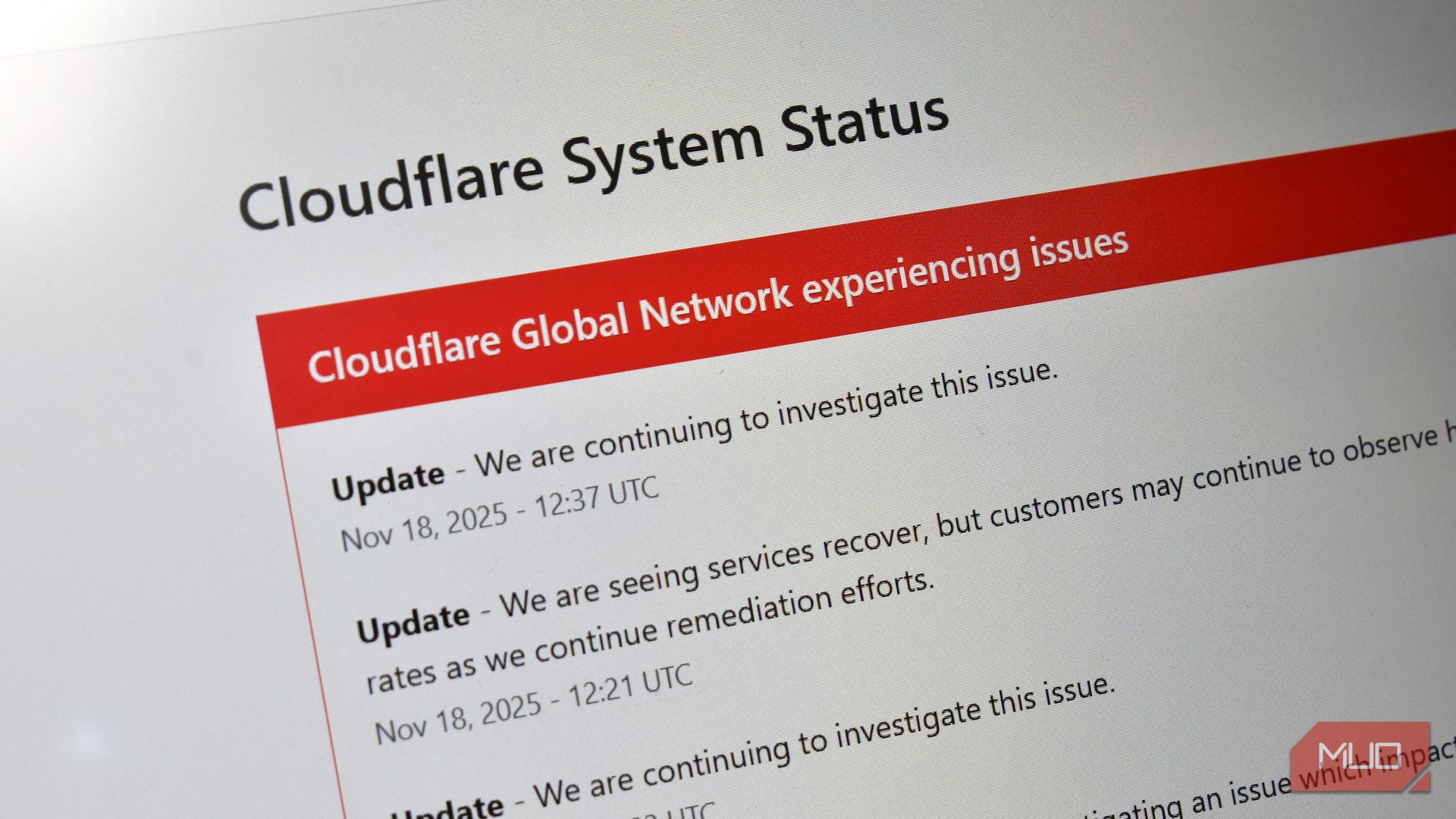
"Investigating - Cloudflare is aware of, and investigating an issue which impacts multiple customers: Widespread 500 errors, Cloudflare Dashboard and API also failing," the message read. A follow-up about 15 minutes later said the company was continuing to investigate the issue. Around 7:20 a.m., the company said services were coming back online. "We are seeing services recover, but customers may continue to observe higher-than-normal error rates as we continue remediation efforts," the message read. By 7:30 a.m., many of the issues appeared to have resolved, at least for some users. Sites like X were accessible again, and DownDetector indicated a drop off in the amount of errors reported. Some users continued seeing issues even after Cloudflare said services were coming back online. By around 8 a.m., the number of errors had leveled off, but didn't appear to be falling in the way they traditionally do when a service disruption is fixed. By 8:10 a.m., Cloudflare said it had identified an issue and was working on a fix to bring all services back online again. Just before 9:45 a.m., the company said it has found the cause of the issue and had fixed it. And in October, a separate incident involving Amazon Web Services, another core pillar of the internet, knocked out service to major websites and apps for over half a day. For over 15 hours, Slack, Snapchat and other well-known tools were knocked offline while their underlying infrastructure was repaired. The outage was not the first time in recent months that Cloudflare issues have disrupted the internet. Large portions of the internet went down in June after a Cloudflare disruption, affecting Twitch, Etsy, Discord and Google. Parts of the web appear to have stopped working amid a technical problem at Cloudflare.
USA Visitors to websites such as X, formerly known as Twitter, ChatGPT and film reviewing site Letterboxd saw an error message that indicated that Cloudflare problems meant that the page could not show.Cloudflare is an internet infrastructure that offers many of the core technologies that power today’s online experiences. That includes tools that protect websites from cyber attacks and ensure that they stay online amid heavy traffic, for instance.“Cloudflare is aware of, and investigating an issue which potentially impacts multiple customers,” the company said in a new update. “Further detail will be provided as more information becomes available.”Tracking website Down Detector, which monitors outage, was also hit by the technical problems itself. But when it loaded it showed a dramatic spike in problems.Affected users saw a message indicating there was an “internal server error on Cloudflare’s network”. It asked users to “please try again in a few minutes”.While Cloudflare has succeeded in returning to its fully operational status by this evening, it’s large scale outage earlier today has prompted questions how likely it is that such an incident will occur again.Lee Skillen, CTO of software artefact management platform Cloudsmith, said: “Although outages are not uncommon, a global "completely down and out" outage like this is absolutely, highly unusual, and there is no doubt that this has a wide-reaching impact worldwide for businesses and their users.
“Modern infrastructure is built on deeply interconnected systems; the more we optimise for scale, the more challenging it becomes to pinpoint how one failure cascades into another. Will this happen more frequently? The shower answer is yes. Expect things to fail.“They can range from mild and short-lived to rare and catastrophic. But they all share one thing: inevitability. Every service with real users will eventually get hit by something; sometimes directly, sometimes indirectly. The greater the magnitude, the greater the possibility.“Today, it's Cloudflare, and tomorrow it may be Fasty, or one of the Cloud provider CDNs. Each is a reminder of how architectural choices ripple outward, exposing an implicit "supply" chain. This is why critical infrastructure providers know they’ve got a (difficult) but important job to do, and invest millions in ensuring that it doesn’t happen.”In an updated notification to their system, the network service said: “Cloudflare services are currently operating normally. We are no longer observing elevated errors or latency across the network.
“Our engineering teams continue to closely monitor the platform and perform a deeper investigation into the earlier disruption, but no configuration changes are being made at this time.“At this point, it is considered safe to re-enable any Cloudflare services that were temporarily disabled during the incident. We will provide a final update once our investigation is complete.”Dane Knecht, Cloudflare’s chief technology officer, has said that their services should now be “fully operational” in his latest update after the internet infrastructure suffered a technical problem.He said: “Sharing an update on the recovery of our services. We were able to resolve the impact to traffic flowing through our network at approximately 14:30 UTC, which was our first priority, but the incident required some additional work to fully restore our control plane (our dashboard and the APIs our customers use to configure Cloudflare).“The control plane should now be fully available. We are monitoring those services and continuing to ensure that everything is fully operational. Again, we plan to share a complete walkthrough of what went wrong today in a couple of hours and how we plan to make sure this never happens again.”
Posted on 2025/11/19 10:07 AM